Soy un Profesional en Informática que me he desempeñado efecientemente en diferentes tópicos de la informática ahora he incursionado en el Comercio Electrónico
Vamos a ver algunos términos relacionados a lo que se refiere a Linux. Nació en el año de 1.991, es un sistema operativo parecido a Unix, Solaris, AIX y más sistemas operativos terminados en X que existen por allí.
Linux es un nombre derivado de Linus Torvalds Unix. Lo cual es un conjunto de programas creadas por Linux Torvalds y un equipo de voluntarios para que se parezcan al sistema operativo Unix.
Linus Torvalds en el año de 1.991 era un estudiante de la Universidad finlandesa de helsinki, cuando creció, la primera versión de Linux la puso en internet, es actualmente lider de un equipo de desarrollo dedicado a Linux, que se puede visualizar en Kernel del linux;
Linux Nucleo o kernel. – Son términos equivalentes. Linux o el núcleo de Linux o el kernel de Linux es el conjunto de programas y archivos que se requieren para trabajar con una distribución de Linux. Linux, por si solo, no es una gran ayuda para el usuario (ni para el técnico). Linux requiere de programas adicionales que vienen con las distribución de Linux
Versiones del sistema operativo Linux.
La primera versión de Linux fue la 0.01 liberada el 17 de septiembre de 1.991 y contenia 88 archivos, con aproximadamente 260 KB.
Una distribución de Linux es un conjunto de programas que trabajan conjuntamente con (y dependen de) el Kernel de Linux y se orientan a satisfacer determinadas necesidades (servidores, estaciones, juegos educativos, cortafuegos, recuperación, gráficos, científico matemático, etc: Existen algunas distribuciones. La lista detallada la encontramos en el link o página Distribuciones de Linux
Unix es el nombre de un sistema operativo creado en 1.970 por Bell Labs (Laboratorios Bell) que luego se transformo en ATT y luego se dividió en varias empresas, incluyendo Bellsouth, Lucent Technologies, entre otras.
Ahora vamos a ver un video sobre la historia del sistema Operativo Linux.
Una base de datos SQL Server es una base de datos cliente-servidor basados en SQL Server; de los cuales utiliza la versión ANSI (American National Standar Institute) del lenguaje de SQL Server.
Los últimos avances de Microsoft que podemos ver en base de datos en el siguiente link:
Las aplicaciones cliente-servidor pueden cubrir una gran cantidad de arquitecturas y sus componentes se pueden crear a través de númerosas herramientas inpependientes relacionados con los lenguajes de programación
Servicios de SQL Server
Existen tres servicios de SQL Server que estos son:
MSSQL SERVER: Administración de datos, procesamiento de consultas y transacciones, e Integridad de datos.
SQL Server Agent: Tareas, Alertas y Operadores.
MS DTC: Administración de transacciones, distribuciones.
Arquitectura de una base de datos.
Sql Server controla las tablas de los datos según las reglas que ellas mismas establecen a través de las tablas de datos. Cuando instala el software de SQL Server automáticamente se crean cuatro bases de datos conocidos como bases de datos del sistema, no se las debe de modificar estas bases de datos y las bases de datos son:
Master
En esta base de datos se encuentra información sobre las cuentas del usuario y la configuración del sistema. Así mismo, tiene información sobre donde se localiza las bases de datos que crean los clientes.
Model:
La base de datos Model es la única de las cuatro que pueden ser modificados con ciertos sucesos. Siempre que se crean otra bases de datos. SQL Server inicia una copia de Model.
Tempdb
La base de datos tempdb es una parte de SQL Server. En Ella se eliminan todas las tablas temporales que se generen durante una ejecución de los procesos.
MSDB
Esta base de datos se utiliza para que el Agent SQL Server guarde la información que necesita para procesos de trabajo y alertas.
Ahora vamos a ver un vídeo de lo que tiene que ver con el concepto de una base de datos
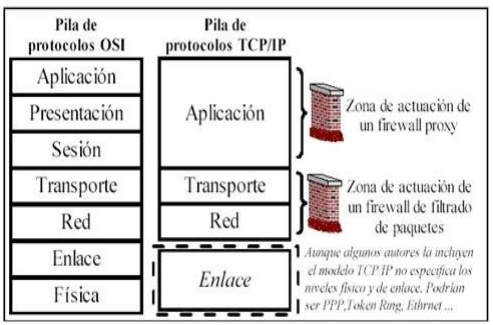
Cuando se creó TCP-IP (en 1973-74), el mundo era diferente; no había preocupación por la seguridad ni por ataques e intrusiones a los sistemas, ni siquiera existía Internet, pero en la actualidad ha cambiado. En la actualidad es indispensable que todo equipo que se conecte a Internet disponga de barreras de seguridad para impedir acceso a personas o programas que quieran ingresar y realizar actividades no autorizadas, como aprovecharse de los recursos y apropiarse de la información.
¿Qué es un cortafuegos?
En informática, un «cortafuego» o «firewall» es un dispositivo de hardware o programa de software que cumple la función de proteger (defender) un equipo o red para evitar accesos no autorizados, ataques o intrusiones hacia un equipo o red.
Un acceso no autorizado es todo aquello que vaya en contra de las políticas definidas por nosotros mismos. De esta forma, dependiendo de las políticas o normas de comportamiento, lo que para una persona o institución puede representar un acceso autorizado, para otras no lo será.
Existen diferentes de cortafuegos, dependiendo del uso, ubicación y reglas que se deseen. Las distintas distribuciones de Linux traen suficientes facilidades para implementar diferentes tipos de cortafuegos adecuados para los tipos de red; pero, además existen paquetes completos para implementar cortafuegos de diferentes tipos.
Componentes de cortafuegos en Linux
Para implementar cortafuegos en Linux se necesitan los siguientes componentes:
Uno o más tarjetas de red funcionando, activas y configuradas con su dirección IP, dependiendo de la función que va a realizar en el servidor.
El componente NETFILTER dentro del núcleo. Este componente viene integrado en los kernel a partir del 2.4 (no tiene las versiones anteriores). Hay ocasiones, que algunos administradores lo retiran al construir un nuevo kernel.
Los módulos IPTABLES, que se puede revisar / instalar con estos comandos
A decir verdad, se puede construir cortafuegos en Linux con menos módulos de los indicados.
El paquete iptables, que debe de estar instalado y funcionando. Para comprobarlo ejecuta el siguiente comando:
rpm -qi iptables
Si fuese el caso de que no se encuentra instalado el paquete se realiza lo siguiente:
yum install iptables
El servicio iptables es el demonio que permite administrar las reglas del cortafuego, los comandos estándar de iptables son
service iptables stop para detener el servicio
service iptables start para iniciar el servicio
service iptables status para ver en pantalla el estado del servicio.
service iptables restart para reiniciar el servicio
service iptables save para guardar la configuración
El comando iptables permite dar una gran cantidad de órdenes desde el teclado o desde una macro para construir las reglas y configurar el cortafuegos.
El archivo /etc/sysconfig/iptables.save donde se guarda la configuración por omisión.
Algunos programas adicionales que permiten ayudar a construir las reglas, como:
system-config-securitylevel.
apf
shorewall
Un ejercicio práctico verifica que el computador donde se realiza la práctica tenga configurada la red y disponga de los programas necesarios, para ellos se usa los comandos necesarios:
modprobe ip_tables
rpm -qi iptables
system-config-securitylevel
system-config-securitylevel-gui
system-config-securitylevel-tui
service iptables status
iptables -L
Verificando el cortafuegos de manera estándar en Centos /Red Hat
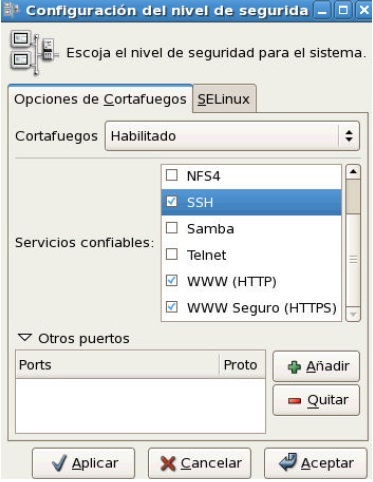
Para verificar de modo gráfico hacemos lo siguiente:
En el menú elija la opción sistema, luego Administración y por último Nivel de Seguridad y Cortafuego.
O también puede escribir el comando system-config-security-level
Nos va aparecer el siguiente cuadro de diálogo:
Para poder habilitar el cortafuegos, seleccione Habilitado, y debe marcar los casilleros con los servicios que se va a permitir (www es navegación en Internet, ssh es el uso de ssh y sscp).
Si se quita el acceso al servicio www solamente significa que otros equipos no podrán utilizar el servicio www (puerto 80) de este servidor. Este cortafuego es bastante limitado y simple, hay otras formas de protegerse, si se quiere dar acceso digamos al servicio ssh, se parará el servicio
service sshd stop
Cortafuegos usando IPTABLES
IPTABLES es el mecanismo de cortafuegos recomendado y el más utilizado en el mundo de Linux, la forma de configurar el cortafuegos es mediante comandos (macros), desde el terminal bash, y que solamente lo debe hacer el usuario root
Se debe de seguir los siguientes pasos para configurar el cortafuegos en iptables:
Asegúrese que el servicio iptables está levantado
Listar las reglas vigentes para analizarlas.
Borrar todas las reglas de todas las tablas.
Definir y activar una política de puertas abiertas o de puertas cerradas.
Crear las reglas.
Grabar las reglas en iptables.save.
Repetir los pasos necesarios para atender las necesidades de la red
Activar y bajar el servicio iptables: service iptables start | stop | status | restart | save
service iptables start Inicia el servicio cortafuegos y activa las reglas vigentes
service iptables stop detiene el cortafuegos, deja el equipo totalmente desprotegido.
service iptables restart Reinicia el servicio (lo baja y lo vuelve a subir) con las reglas vigentes
service iptables save Graba las reglas vigentes en el archivo /etc/sysconfig/iptables.save que serán utilizados en el siguiente reinicio.
chkconfig iptables on Activa el servicio iptables al reiniciar el equipo.
Listar las reglas vigentes con el comando iptables – L
El comando iptables -L muestra en pantalla las reglas de cortafuego
Tablas de iptables
Hay cuatro tablas principales para implementar las reglas en iptables; que estas son:
Tabla
Descripción
filter
Es la tabla por omisión que contiene las reglas de filtrado de paquete. Si es que no se indica ninguna tabla, asume –t filter
Iptables –L muestras las reglas de la tabla filter
Iptables –t filter –L muestras las reglas de la tabla filter
Iptables –t filter –F Borra las reglas de la tabla filter
Iptables –P INPUT ACCEPT (las políticas de la tabla filter son aceptadas)
Es la table que permite NAT (Network Address Translater) y PAT (Port Address Translation).
Iptables –t nat –L list alas reglas de la table nat
Iptables –t nat –X Borra las reglas de la tabla nat.
mangle
Es la tabla que permite manipular y convertir paquetes desde un formato a otro.
raw
Es la tabla “en crudo”, o sea el cual el sistema la utiliza
Como borrar las reglas . Iptables -F e Iptables-X
El comando iptables -F borra las reglas de la tabla indicada, si las usas inmediatamente debe crear nuevas reglas.
iptables -t filter -F
iptables -t nat -F
iptables -t mangle -F
iptables -t raw -F
iptables -t filter -X
iptables -t nat -X
iptables -t mangle -X
iptables -t raw -X
Reglas de iptables
Cada una de las tablas tiene un conjunto de reglas
Tabla
Regla
filter
En está tabla se lleva a cabo la principal tarea de iptables: el filtrado de paquetes, consta de tres cadenas predefinidas:
INPUT son los paquetes entrantes cuyo destino es el propio host.
FORWARD son los paquetes que llegan al cortafuegos y tiene como destino otro host, podemos decir encaminados.
OUTPUT son los paquetes generados en el propio host con destinos externos.
nat
Se utiliza para el protocolo Network Addess Translation. Cuando un flujo
de paquetes (una conexión TCP) atraviesa la tabla, el primer paquete es
admitido, el resto son automáticamente identificados como parte del flujo
de ese primer paquete y de manera automática se llevan a cabo sobre ellos las operaciones NAT o de enmascaramient o. Esta es la razón por la
cual no se lleva a cabo ningún tipo de filtrado en esta tabla. La tabla de nat
tiene tres cadenas sobre las que podemos añadir reglas. La cadena
PREROUTING se utiliza para alterar los paquetes tan pronto llegan al
cortafuegos (DNAT o NAT del destino). La cadena OUTPUT se utiliza para
alterar los paquetes generados localmente dentro del cortafuegos, antes
de tomar ninguna decisión de enrutado.
mangle
La tabla de mangling o “manipulación” permite manipular elementos de los
paquetes, como el TTL, el TOS, etc…, a excepción del NAT, que se realiza
en la otra tabla. La funcionalidad de esta tabla está en expansión y,
aunque potencialmente puede ser muy valiosa, no tiene demasiada utilidad
(salvo para hackers). Consta de dos cadenas, PREROUTING y OUTPUT.
Políticas de Iptables
Linux permite ajustar las reglas a las necesidades del administrador. Muchos administradores prefieren empezar con las barreras totalmente cerradas (Políticas RESTRICTIVA o DROP), mientras que otros administradores prefieren iniciar con las barreras totalmente abiertas (Política PERMISIVA o ACCEPT)
Para iniciar una política restrictiva, se utiliza la palabra DROP de esta manera:
iptables -P INPUT DROP
Lo que quiere decir que todo lo que ingrese al host y que tiene como destino el mismo host, es vertido sin mensaje de error. En resumen, todo el tráfico entrante es ignorado.
iptables -P OUTPUT DROP
Quiere decir que todo lo que sale de este host con destino a otros hosts, es vertido sin error, en definitiva todo el trafico saliente es ignorado.
Si deseas conocer mas de este comando iptables, ingresa al siguiente link
TCP / IP (Transmision Control Protocolo / Internet Protocolo) es el nombre dado a una colección de protocolos (conjunto de reglas de lenguaje y comportamiento) creadas entre 1973 y 1974 por Vicent cerf y Robert Kahn para intercomunicar redes de computadora.
TCP / IP siginifica «Protocolo de Control de Transmisión / protocolo de Internet» y se pronuncia por separado «T-C-P-I-P»
Fue originalmente diseñado para sistemas operativos UNIX, pero se volvió un estándar para cualquier dispositivo conectada a Internet.
Sin los protocolos «TCP/IP» no hay Internet. No es posible el acceso a la red mundial Internet si el computador no entiende o no tiene funcionando adecuadamente el conjunto de protocolos TCP/IP
Características fundamentales del protocolo TCP/IP
Todo computador conectado a la red TCP /IP debe de tener una dirección IP única.
Todo computador conectador en red TCP / IP debe de tener una máscara de red para conocer la red a la que pertenece
Tanto la dirección IP como la máscara de RED deben de pertenecer a la misma red o ser compatibles con ella.
Todo computador que se conecte a Internet debe tener la dirección IP de su «Puerta de Enlace» y su «Servidor de Nombres», el proveedor de Internet o el administrador de la red deben proporcionar estas direcciones.
Un computador conectada en red puede tener un nombre de equipo (hostname).
Los diferentes programas que implementan el protocolo TCP / IP se encargar de intercambiar la información entre los computadores, respetando reglas y formalismos preestablecidos, dividiendo los mensajes, enrutando los mensajes, detectando errores y solicitando retrasmisiones.
Dirección IP
La dirección IP identifica de manera única a un equipo ( o dispositivo) dentro de la red. Es la identificación única de un HOST y debe respetar ciertas reglas: podemos evitar decir a cada momento equipo, dispositivo, router, MODEM, etc. se acostumbra decir simplemente HOST. Entonces podemos decir que HOST es cualquier dispositivo o computadora dentro de una red, no pueden existir al mismo tiempo dos HOST con la misma dirección IP en Internet ni en la red Interna.
Ejercicio práctico: para confirmar que Internet trabaja con direcciones IP, escribe en la barra de
direcciones de tu navegador (cualquiera, con tal que esté conectado a Internet) lo siguiente: http://64.233.161.104 y presione ENTRAR. Indica qué ocurre, ¿qué página se abrió? Si
no se abrió el conocido buscador, revisa tu conexión a Internet. Notarás que la página se
despliega ligeramente más rápido cuando utilizas la dirección IP que cuando utilizas el nombre
de equipo, debido a que internamente todos los nombres de equipo se convierten a direcciones
IP como paso previo al intercambio de información.
Vamos a ver la dirección IP en detalle:
Dirección IP
ID de Red (Network)
ID de Host
192.168.56.1
192.168.56.
1
192.168.56.6
192.168.56.
6
64.233.161.104
64.233.
161.104
65.122.12.4
65.122.
12.4
10.8.3.4
10.
8.3.4
10.0.0.1
10.
0.0.1
Observemos que los dos primeros equipos (filas 1 y 2 de la tabla) están por defecto en la misma network o red. Todos los hosts que pertenecen a la misma red requieren el mismo número de red para que se comuniquen directamente.
El sistema operativo Linux fue diseñado y desarrollado con la TCP/IP en mente. TCP/IP, Internet y la gran ventaja que tienen las redes que conocemos actualmente, existen gracias a Unix. Como Linux es un derivado de Unix sus capacidades para trabajo de redes son extremadamente potentes.
Una maquina Linux puede actuar puede actuar como cliente de red o como servidor de diversa naturaleza: servidor de comunicaciones, servidor de correo, servidor de proximidad, servidor de archivos, servidor de audio, etc. Prácticamente todos los servicios de Internet.
En una máquina Linux las actividades que se pueden realizar como cliente y son los siguientes:
Navegar en Internet (con navegadores de Linux: Firefox, Konqueror, Nautilus, Mozilla, Netscape)
Enviar y recibir mensajes con programas cliente de correo: mail, kmail, evolution
Transferir archivos usando ftp, gftp, ssh, scp.
Usar conexiones remotas en modo texto y modo gráfico con ssh, telnet (obsoleto), uucp (obsoleto), vnc (modo gráfico)
Utilizar diferentes servicios de red: Real Audio, tv, noticias, correos, páginas web, servicios web, comercio electrónico, etc.
Como servidor, Linux tiene una amplia gama de posibilidades:
Servidor de páginas web
Servidor de archivos nfs (red Local Linux)
Servidor de archivos Samba (red local Windows)
Servidor de archivos ftp (Internet)
Servidor de Nombres DNS.
Servidor de configuración dinámica de host (DHCP)
Servidor de proximidad proxy
Servidor de correo.
Cortafuegos (iptables)
Servidor de fax
Servidor de telefonía voip
Servidor de VPN (Red Privada Virtual)
Servidor de Autentificación (Radius, Kerberos, LDAP, etc)
Conceptos Importantes en uso de las redes
Término
Equivalencia
Interface
Tarjeta de red, que puede ser física o virtual
MAC
Medium Access Control Address un número de 48 bits (6 bytes) que identifica (generalmente de forma única) a una tarjeta de red a nivel mundial, por ejemplo: 00:1C:4B:2F:39:12. En Linux se conoce como HWADDR (Hardware Address)
Broadcast
Es la técnica que permite enviar mensajes a toda la red para que responda el equipo correcto que brinda el servicio deseado.
TCP/IP
Transport Control Protocol / Internet Protocol. Familia de protocolos o conjunto de reglas que permiten y facilitan la comunicación entre diversos equipos y dispositivos, basados en la dirección IP.
Dirección IP
Un número que identifica un equipo en la red. Por ejemplo: 192.168.2.30
IP V4
Es la versión 4 del protocolo IP que utiliza cuatro cifras para la dirección IP.
IP V6
Es la versión 6 del protocolo que utiliza 128 bits para identificar la dirección IP.
Servidor de Red
Un computador que ofrece (publica) servicios de red (almacenamiento, comunicaciones, Proxy, archivos, audio, páginas web, video, resolución de nombres, configuración, etc).
Cliente de Red
Un computador que utiliza servicios de red (se conecta a uno o más servidores).
DHCP
Dynamic Host Configuration Protocol. Uno de los integrantes de los protocolos de la familia TCP/IP que permite a un servidor brindar información para que los clientes de red configuren sus interfaces automáticamente ( o dinámicamente, que es lo mismo).
DNS
Domain Name Server o Servidor de Nombres de Dominio, es un servidor que traduce los nombres de los equipos (por ejemplo www.google.com ) a su dirección IP equivalente.
Gateway
Puerta de Enlace. Un servidor de comunicaciones o un dispositivo que conecta dos redes entre sí.
Firewall
Cortafuegos. Un servidor o dispositivo que brinda cierto nivel de seguridad entre dos redes permitentes y restringiendo los accesos.
Ifconfig
Comando utilizado para ver la configuración de la red.
Interfaces de redes
En el sistema operativo Linux, las tarjetas de red se llaman interfaces. En Linux las interfaces (de red o de otra naturaleza, como discos, audio, video) están en la carpeta /dev y tiene nombres como eth0, usb0, tap0, sat0, en donde el 0 significa el primer interface, mientras que los sucesivos números indican las siguientes tarjetas o interfaces.
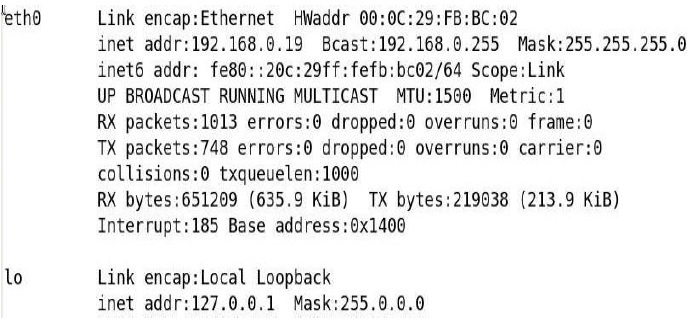
Al ejecutar el comando ifconfig desde el Shell del Linux al ejecutar nos muestra lo siguiente:
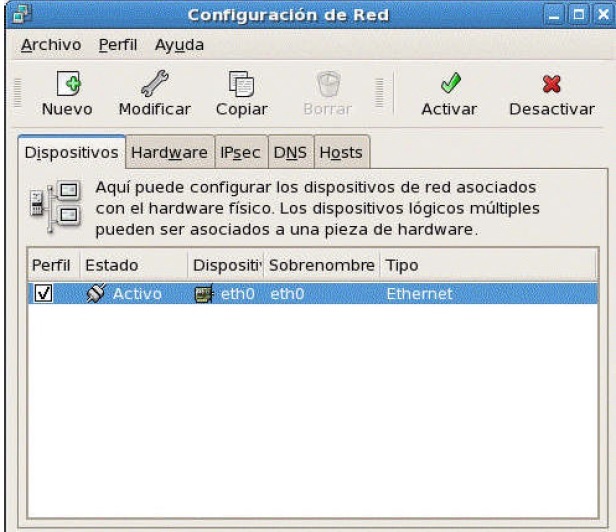
Revisar la configuración de la red en modo gráfico
Para revisar la red de modo gráfico hay dos maneras de revisar en Linux:
A partir del comando system-config-network-gui
Desde el menú del Linux seleccionamos, Sistema, del submenú administración y luego Red.
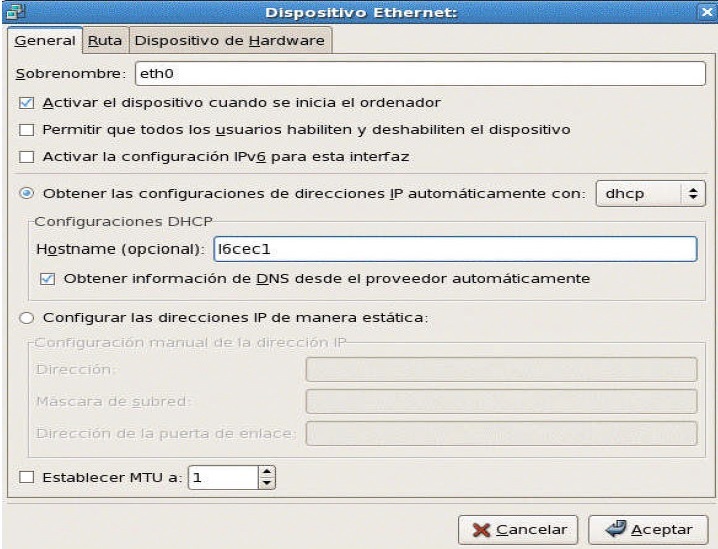
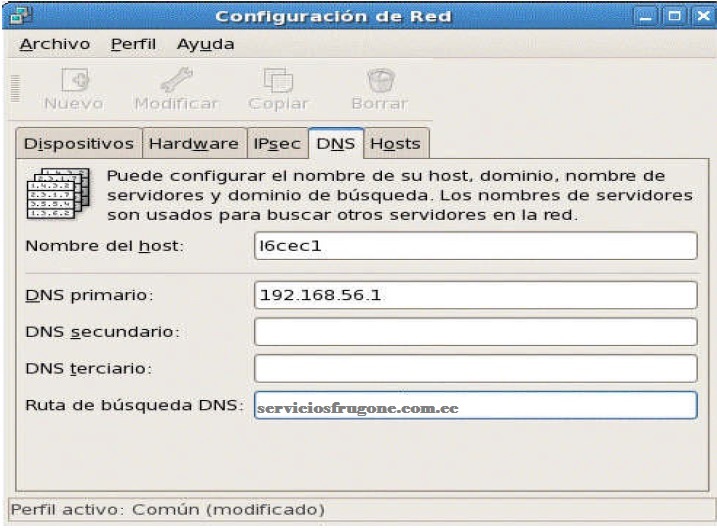
Aparece una pantalla gráfica para revisar/modificar la configuración de la red. Este programa presenta varias pantallas, cada una de ellas muestra elementos de la configuración.
Las tarjetas ethernet se conoce como eth0 (la primera); eth1 la segunda, y así sucesivamente.
Revisar la configuración de la red en modo texto
Para revisar la red en modo texto se lo puede utilizar a través de varios comandos desde la sesión del Terminal Bash
Comando ifconfig
El comando ifconfig es muy complejo y lo dejaremos más adelante, por lo que este comando sin argumentos nos presenta lo siguiente:
Comando ifconfig
Visita este link donde podrás encontrar más información acerca de las redes de Linux
Como sabemos que en algún momento dado los servidores pueden ser atacados y no es la mejor solución en apagar el servidor y dejar de usarlo, hay otras medidas de seguridad.
No es el hecho que en seguridad se recuerde de que un servidor halla sido atacado, sino haber tratado de prevenir que esto ocurra, ya sea actualizando el sistema con yum o tomando médidas físicas o virtuales para evitar que un atacante accede al servidor.
Lo más importante es darse cuenta rápidamente que ha sido atacado y tomar las medidas adecuadas lo más pronto posible. Lo primero que debemos hacer es, reinstalemos el sistema.
Usamos el paquete aide, que nos permite crear una base de datos con nombres, tamaños y características de los archivos y directorios de nuestro sistema y que, cada cierto tiempo, verifica que estos no hayan sido alterados.
Uso de aide (advanced instrusion detection environment)
Instalación
Centos libera una versión del aide que lo podemos instalar ejecutando
yum install aide
Configuración del aide
Antes de usar el aide por primera vez debemos tomar en cuenta en qué estado esta el SELINUX.
Verifiquemos la variable SELINUX en este archivo
cat /etc/sysconfig/selinux
# This file controls the state of SELINUX on the system.
#SELINUX= can take one of three values:
#enforcing – Selinux security policy is enforced.
#permissive – SElinux prints warnings instead of enforcing
#disabled – SELINIX is fully disabled
SELINUX=disabled
#SELINUXTYPE = type of policy in use. Possible values are:
#target = Only target targetet network daemons are protected.
#strict – Full Selinux protection.
SELINUXTYPE=targeted
# SETLOCALDEFS = Cheks local definitions changes.
SETRLOCALDEFS=0
Si tuviéramos está variable activada (enforcing) o en modo permisivo (permisive), podríamos con la siguiente sección (inicialización de la aide), al observar lo tenemos desactivado.
Cuando esta desactivada hacemos los siguientes pasos:
Copia el archivo de configuración hacia /etc/aide.conf
Cambiarle al dueño de root y ponerle permisos 600
chown root.root /etc/aide.conf
chmod 600 /etc/aide.conf
El aide, con su archivo de configuración original, comete muchos errores en caso de que tengamos el SELinux deshabilitado. Por eso hay que sustituir el archivo.
Inicialización de la BD
El aide necesita de que tomemos una foto inicial de como esta el sistema, a esto se llama inicialización, lo que es una compilación y todos los archivos y directorios del sistema, para tener la certeza de que estas propiedades no hallan sido alteradas antes de la inicialización que ejecutaremos ahora:
aide – init
AIDE, versión 0.13.1
AIDE database at /var/lib/aide/aide.db.new.gz initialized.
En tiempo que demore dependerá de la cantidad de archivos y directorios que tengamos en el sistema. Al finalizar, fíjense que dice que se inicializó la BD y tiene un nombre /var/lib/aide/aide.db.new.gz
Esta es la BD recien creada. Se lo debe copiar con otro nombre:
Cada vez que tengamos la necesidad o el interés de ver cualquier archivo que haya cambiado en nuestro sistema ejecutamos:
aide – check
Este comando tarda un buen rato, lo que hace es comparar el estado actual de nuestro sistema con la BD inicial que hemos creada.
Cambios naturales en el sistema
Hay ocasiones que en nuestro sistema, ocurren cambios importantes y conocidos, como el hecho de que hemos borrado uno o varios paquetes o hemos instalado o actualizados nuevos.
En este caso podríamos actualizar la BD con el comando
Este comando actualizará la BD de forma tal que esos cambios no continúen saliendo como mensajes
Ejecutándo el aide diariamente
Podemos crear un script que lo llamarremos /usr/sbin/aidecron.sh que diga algo así:
#! /bin/bash
/usr/sbin/aide — check | /bin/mail -s «Reporte de aide» mail@dominio.com
exit 0
Vamos a dar derecho de ejecución:
chmod +x /usr/sbin/aidecron.sh
Creamos una tarea del cron (crontab -e) que lo ejecute todos los dias a una determinada hora, por ejemplo:
0 6 * * * /usr/sbin/aidecron.sh &> /dev/null
Con esto lograremos que el sistema se ejecute todos los dias y nos mande un mensaje a mail@dominio.com
Rkhunter
Se acaba de explicar lo que es aide, que es buena y útil. Es aplicación compleja con reportes exhaustivos que algunas veces las empresas no requieren.
Un tiempo atrás surgió una nueva alternativa, llamada rkhunter (Cazador de rootkits, rootkits hunter), que esta en http://www.rootkits.nl que realiza funciones similares al chkrootkit, pero cxon algunas ventajas:
Tiene un ciclo de actualizaciones más rápidos que el chkrootkits.
Permite actualizaciones de la BD de rootkits automáticamente.
Permite actualizaciones del programa automáticamente.
Tiene un esquema de reportes más amigables que el chkrootkits.
Instalando rkhunter
Si es que no se ha instalado instale primero el rpmforge desde el sitio RPM Forge
Existen diferentes tipo de Shell en Linux, se puede ver la lista en /etc/Shells, el Bash es el shell más popular en el mundo de Linux, hay personas que consideran que Bash es la única Shell que existe para Linux.
Podemos usar el Bash sripting para realizar tareas repetidas con frecuencia. Los programadores, por razón de rapidez y eficiencia, crean sus aplicaciones en un lenguaje de alto nivel, en el caso de Linux lo hace en C, el Shell de Linux tiene un excelente rendimiento en la ejecución por lotes.
Antes de comenzar veamos una curiosidad: en Bash scripting se puede anotar los comandos tal y como se escribe en nuestro Shell, por ejemplo:
pwd
date
cat /etc/termcap
Comandos multilinea.
También podemos escribir varios comandos en una sola línea, separados por punto y coma «;». Probemos a ejecutar estos comandos a la vez:
echo $LOGNAME;pwd; date
Lo que hemos hecho es imprimir una variable (LOGNAME), inmediatamente después, imprimir el directorio actual (pwd) y, al final, la fecha del sistema.
El archivo de script
Hasta ahora hemos probado comandos aislados o en muy poca cantidad. Ahora vamos a ejecutar varios comandos simultaneamente y los guardaremos en un archivo. Es decir, vamos a colocar los programas de Bash dentro de un solo archivo, que le pongamos un nombre terminado con .sh
Programación en Shell Scripting en Linux
Vamos a ver cada uno de los detalles y, no hay que olvidar en practicar y practicar.
El símbolo # indica comentario. Los scripts suelen encabezarse con comentarios que indican el nombre del archivo y lo que hace el script. También se puede colocar comentarios de documentación en diferentes partes del script para mejorar la comprensión y facilitar el mantenimiento. Un caso especial es el uso de # en la primera linea para indicar el interprete con que se ejecutará el script. Esta linea indica que el script será ejecutado con el interprete de comandos Bash. Esta indicación debe estar en la primera línea del script y no puede tener blancos.
Echo es un comando de impresión de texto en pantalla; se imprime todo lo que hayamos puesto en comillas, si se debe imprimir el valor de una variable debe de anteponerla un $ delante. Por ejemplo $HOME (seguramente /home/nombrede usuario) y $LOGNAME imprimirá nombre de usuario. Si se agrega el switch -n imprimirá la cadena pero sin agregarle ENTER al final.
Para ejecutar los comandos contenidos en este archivo, se necesita darles permisos de ejecución:
chmod ug+x holamundo.sh
La invocacion (ejecucación) del archivo puede realizarse dando el nombre del archivo como argumento a Bash:
bash holamundo.sh
Finalización de los script
Al finalizar un script no tenemos que poner nada especial, aunque se sugiere que utilices exit 0
El comando exit finaliza ahí mismo la ejecución del script. El número que sigue al comando exit («0» en este caso) termina el script devolviendo 0, y si tuvo un error se devuelve otro valor diferente de 0.
Uso de variables
Las variables son uno de los temas más interesantes de programar Shell scripting ya que se utilizan sin necesidad de declararlas previamente ni de definir su tipo de dato. Por ejemplo:
#! /bin/bash
a=»Hola Mundo»
temp=15
echo «$a la temperatura es $temp grados celsius»
exit 0
En este caso hemos definido dos variables:a y temp. Al darle valor a una variable no usamos el signo de $ delante. Se debe de tener en cuenta que para hacer uso de una variable anteponemos el signo de $ delante. El comando echo usa : $a y $temp.
La salida del comando dirá:
Hola mundo la temperatura es de 15 grados celsius.
Uso de backtick
Existen tres tipos de apostrofes en nuestro teclado:
‘ : El apostrofe normal que está típica mente situada a la derecha del 0 en los teclados en español.
´: El backstick que esta situado a la derecha de la letra P en el teclado en español.
^ : Lo que esta al lado de la ñ en el teclado en español y que no lo usaremos.
En el caso del teclado en inglés tenemos solo dos:
el apostrofe normal ‘ esta al lado del ; (punto y coma)
el backstick ‘ esta a la izquierda del 1 (debajo de la tecla escape)
El backstick es muy importante porque nos sirve para ejecutar un comando y asignar la salida del comando a una variable. Es decir, no se mostrará el comando ni su salida, sino que se tomará su salida y se lo asignará a una variable.
Programación en Shell Scripting
Pero ¿Que hace el shitch wc-l de la instrucción cat?
En este caso lo que hace es contar las lineas que tiene el archivo /etc/passwd
ejemplo:
#! /bin/bash
cant=’cat /etc/passwd|wc-l’
echo «El sistema tiene $cant usuarios»
exit 0
Para consultar mas de la programación en Shell Scripting de Linux ingresa al siguiente Link o enlace:
Concepto avanzado de unidades de almacenamiento RAID
Para prevenir imprevistos por fallas mecánicas de hardware en nuestro sistema de almacenamiento tenemos lo que se llama «RAID», que sus siglas en Inglés «Redundant Array Of Inexpensive Disks», lo que indica que es una tecnología que permite tener máquinas más resistentes a fallas físicas en los discos, pues su objetivo es de tener información que se guarda en los discos, disponibles en dos o más de ellos.
Si uno falla, no hay problema, el sistema sigue funcionando con los demás discos disponibles.
RAID es un sistema que duplica (o triplica más) la información que escribes en un disco, ya que copia en los otros discos.
Raid 0
Es sencillamente poner dos o más discos a trabajar en paralelo.
El RAID 0, conocido como Stripping o redundancia 0, es útil para aumentar el tamaño de los discos; por ejemplo, tengo dos discos de 500 GB, pero se desea tener un volumen de 1 TB, para eso los uno y tengo 1TB.
Así el filesystem usa todos los discos como si fuera un volumen, lo que, por supuesto hace que surja un problema.
El problema del RAID 0 es que en caso de falla de uno de los discos RAID, se pierde toda o casi toda la información.
Si la herramienta de Linux mdadm utiliza RAID-0 puede lograr distribuir la forma en que se escribe la información. Por ejemplo, supongamos que se tiene dos discos RAID-0 , es posible escribir un byte (que sosn ocho bits) en los dos discos (4 bits en cada disco), de tal forma que se puede aumentar la velocidad de escritura al doble (no se baja un cabezal del disco, sino que se baja los cabezales en paralelo).
RAID-0 tiene las siguientes ventajas:
Puede ser potencialmente mente rápido en la lectura.
puede aumentar el tamaño de un volumen.
puede ser potencialmente rápido en la escritura.
También hay desventajas, di uno de los componentes (discos) falla se pierde casi toda la información contenida.
RAID-1
Es uno de los más populares y conocidos. Tiene otros nombres como:
Mirroring.
Espejo
Redundancia 1
Este RAID crea una copia exacta de los discos que usemos. Requiere de 2 o más discos, preferiblemente del mismo tamaño.
En el RAID-1 no se aumenta el tamaño de los discos por agregar más discos, sino que disminuye la posibilidad de perder información por un fallo físico. Es decir, si pones dos discos de 80 GB, tendrás al final un volumen RAID-1 de 80GB, y si pones 8 discos de 80 GB en RAID-1, tendrás un volumen de RAID-1 de 80GB.
Al mantenerse una copia exacta en cada disco de RAID-1, es posible, por lo tanto, leer la información de cualquiera de ellos.
RAID-1
Ventajas de RAID-1
100% redundantes.
La velocidad de escritura incrementa CD*X
La velocidad de las escrituras se mantienen igual a X.
Es uno de los más populares.
Desventajas de RAID-1
No aumenta el tamaño del volumen; es decir, no aumenta la capacidad de almacenamiento.
Se sugiere para soluciones al bajo costo, pues puede armarse con discos del mismo tamaño.
RAID 1+0
Es el tipo de RAID compuesto más utilizado. Es una combinación de RAID-0 y RAID-1 y como resultados obtendremos RAID-1.
Supongamos que se tiene los discos 1,2,3 y 4
Hacemos un RAID-0 entre 1 y 2 (lo llamamos A)
Hacemos un RAID-0 entre 3 y 4 (lo llamamos B).
Entonces hacemos un RAID-1 entre A y B
De esta forma logramos realizar un volumen CD*2
Ventajas:
Las lecturas se pueden incrementar en CD*X
Las escrituras se pueden incrementar en CD*CX/2
El sistema es redundante.
Logro tener volúmenes más grandes (que no tenía RAID-1)
Desventajas:
El costo es bastante grande, pues requiere de 4 discos como mínimo
RedHat fue el pionero en el mundo de Linux por su forma elegante y práctica para manejar paquetes; para eso se creó desde un inció, un sistema que permitía mantener un control completo sobre todos los paquetes instalados en el sistema operativo.
Gracias a RedHat podemos saber que paquetes tenemos instalado en el sistema y a que archivo pertenece cada paquete. De esta forma, podemos tener un control preciso a la hora de actualizar, instalar o eliminar un paquete.
RPM, son las siglas de ReadHat Package Manager, es capaz de detectar dependencias de paquetes, de forma tal, que nunca un paquete se instalará si falta una dependencia de él. Por ejemplo, para poder tener instalado el php que es un lenguaje interprete que majera páginas WEB dinámicas , normalmente hace falta que este instalado el httpd (apache), pues sino el php no tendría sentido.
Otro ejemplo para poder instalar el webmail que esta el php hace falta que este instalado el php
Lo mismo sucede, a la hora de desinstalar un paquete, si se intenta borrar el httpd usando comando del rpm, nuestro rpm dirá que no lo podrá borrar, pues otros paquetes dependen de él, y nos indicará la lista de paquetes (php por ejemplo) que necesitan del httpd; si queremos borrar el http, tendremos que eliminar el php, que fallará, ya que uso el webmail.
Usando rpm
El comando rpm tiene un switch llamado q, que permite hacer preguntas (queries) de la BD de los paquetes, por ejemplo:
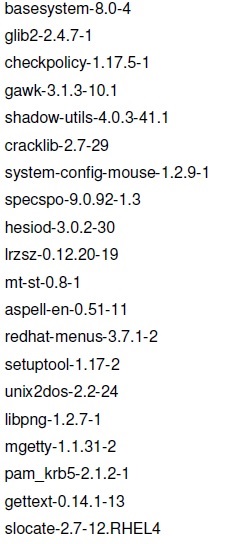
rpm -qa
Nos dirá la lista de paquetes instalados en el sistema.
Lista de paquetes usando rpm
Si queremos tener información de un paquete especifico, lo hacemos con rpm -qi apmd
Información de un paquete con rpm -qi <nombre-del-paquete>
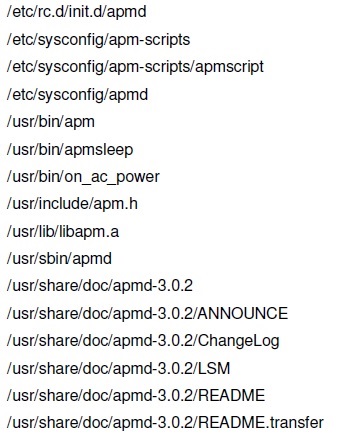
Para ver la lista de archivos que componen un paquete lo hacemos con el siguiente comando rpm -ql apmd (en este ejemplo vamos a ver la lista de archivos del paquete apmd)
Lista de archivos de un paquete
Para saber a que paquete pertenece un archivo hacemos lo siguiente rpm -qf /etc/passwd
setup-2.5.37-1.1
Lo que hace este comando dar información a que paquete pertenece este archivo /etc/passwd
Vemos que el paquete se llama setup.
Pues bien ya hemos visto información del paquete que pertenece un archivo con el comando rpm -qf /etc/passwd; ahora bien podemos eliminar un paquete con la siguiente instrucción en Linux rpm -e apmd (en este caso le decimos que borre el paquete apmd)
La utilidad que tiene de borar un paquete tiene la siguiente finalidad:
Ahorrar espacio en disco.
Eliminar potenciales conflictos entre diferentes aplicaciones.
Ahorrar inodos.
Eliminar posibles fallas de seguridad. Si no tenemos instalada la aplicación, aunque tenga una falla de seguridad no la podrán usar, pues está eliminada y no existe.
Instalando y actualizando paquetes.
Para poder instalar y/o actualizar paquetes en Linux usamos el siguiente comando en Linux
rpm -Uvh nombre del paquete.
U: actualiza el paquete si ya existe, o instalarlo si no existe.
v: verbose, dar información extendida de cualquier evento que ocurra.
h: hash, mostrar un signo de # que va progresando, para ver como va desarrollando la acción.
nombre del paquete: Es cualquier paquete rpm que hayamos bajado.
Los paquetes que podemos instalar son altamente independientes de la versión de la distribución que ejecutemos, por lo tanto, si tratamos la versión 5 de centos solo debemos bajar paquetes o instalar paquetes de centos-5, conocidos como EL5.
Cada paquete viene previamente compilado para su propia versión de Linux (suse, mandrake, centos3, rhel3, etc) tiene sus propias y diferentes librerías, y aunque podríamos a forzarle a hacerlo, y de hecho incluso podríamos ver que este bien instalado y sin problemas, seguramente no ejecutara bien.
Reconstruyendo la BD de rpm
Hay ocasiones que la BD de rpm se daña, las razones son diversas y los síntomas variados lo que no ocurre con frecuencia, para poderla reconstruirla se hace lo siguiente:
rpm –rebuilddb
Al ejecutar este comando se hará la reconstrucción de la BD rpm para eliminar cualquier inconsistencia que se encuentre.
Lo que es un comando que no es dañino, se puede ejecutar cada cierto tiempo para estar seguro que todo este bien.
Instalaciones y actualizaciones vía Internet.
Manejos de paquetes YUM
El manejo de un sistema actualizado es la base fundamental para cualquier implementación de un sistema de seguridad. No solo debemos de conformarnos de tener un sistema operativo bien renombrado sino lo podremos mantener actualizado.
La cantidad de fallas de seguridad detectadas cada día es inmensa y se hace extremadamente necesario implementar una correcta política de actualizaciones si no queremos ser invadidos mediante fallas de seguridad conocidas.
El yum es una utilería que nos permite conectarnos al sitio de actualizarnos de CentOS de forma automática o manual para realizar actualizaciones o instalaciones de paquetes.
Servicio YUM
Yum puede correr un servicio a las 4AM todos los días; para ello podemos activarlo para que diariamente a las 4AM se conecte a los servidores remotos de CenTOS para verificar si hay que actualizar algún paquete, y así proceder con la actualización.
Para activarlo se hace lo siguiente:
chkconfig –level 2345 yum-updatesd on
service yum-updatesd start
Con esto bastará para que todos los días, en la madrugada, se actualice nuestro sistema.
Yum deja una copia de todos los paquetes en /var/cache/yum
El comando para actualizar la lista de paquetes en nuestro sistema es:
yum update
Este proceso tardará un poco, dependiendo de la cantidad de paquetes que hallas instalado y que tengas que actualizar. El proceso interno es el siguiente:
Lee el archivo /etc/yum.conf y el directorio /etc/yum.repos.d para verificar a que repositorio se conectara.
Se conectará a todos los repositorios indicados en /etc/yum.repos.d/ y bajará una lista de potenciales actualizaciones ofrecidos por ellos.
Dadas estas listas, procederá a comparalas contra los paquetes ya instalados en el sistema y determinará lo que deben actualizarse.
Nos indicará los paquetes que estima debe actualizar y pedirá que confirmemos (y) si queremos, para proceder.
Bajará a /var/cache/yum los paquetes .rpm que debe actualizarse.
Una vez bajado los paquetes, los actualizará (que es idéntico a rpm -Uvh)
El paso 4 lo podemos obviar si hacemos:
yum -y update
Conoce algo mas del comando YUM para actualizar linux por Internet en el siguiente link o enlace:
Syslog es el servicio que utiliza Linux para guardar los mensajes que los otros demonios del sistema necesitan guardar.
No es recomendable de que cada demonio guarde por su lado los mensajes, puesto que el trabajo de guardar los mensajes es, muchas veces pesado, y debe tratar de coordinarse para ahorrar recursos. No es lo mismo que 5 o 50 demonios tratando de escribir en un mismo archivo, que 5 o 50 demonios enviándoles mensajes al syslog, que se encargada, en su debido momento, de escribir mensajes en el disco, coordinando las escrituras y, sobre todo, ahorrando acceso de escritura innecesaria al disco.
Los siguientes servicios necesitan escribir dentro de /var/log/maillog, que es un archivo.
servidor de smtp (servidor de correo)
servidor de POP3 (una variante que posteriormente estudiaremos para leer los correos).
servidor de IMAP (otra variante que posteriormente estudiaremos para leer los correos)
Sistemas antivirus y antispam.
Todos ellos independientes, separados, a los efectos de nuestro sistema operativo Linux
Activando el syslog
Para verificar si esta activado se ejecuta el siguiente comando
chkconfig –level 2345 syslog on service syslog start
Con esto el syslog esta activo.
Un mensaje syslog se compone de tres partes:
Facilidad (facility) a la que emite el mensaje. Se puede utilizar 12+8 facilidades .
Prioridad (priority) conque se emite el mensaje. Existen 8 prioridades con que se emite el mensaje.
El mensaje en sí. Que es una cadena de texto de libre uso.
El formato del archivo /etc/syslog.conf es el siguiente:
facilidad.prioridad /camino/a/archivo.log
Veamos un ejemplo; se puede definir en el archivo /etc/syslog.conf estas dos lineas:
mail.info /var/log/messages
mail.* /var/log/maillog
La primera linea significaría una orden para syslog, algo como que: «cualquier mensaje enviado a la facilidad mail, con una prioridad info, guárdalo en /var/log/messages.
La segunda línea diría: «Cualquier mensaje emitido a la facilidad mail, con otra prioridad, guárdalos en /var/los/maillog
Facilidades en Linux
Los niveles de prioridad (priorities) en los mensajes son los siguientes:
Niveles de prioridad
Para ver algo mas de acceso remoto y lectura de Logs te invito a ver este video
El Grub es la única aplicación del BIOS que en Linux se carga que se encargará de ejecutar el kernel del sistema operativo Linux.
Las características del Grub tenemos los siguientes:
Ofrece una interfaz semigráfica muy intuitiva (menús y recuadros de textos) al arrancar. Es personalizado e incluso en color si así lo deseamos.
En cualquier momento podemos editar los parámetros de las opciones del menú de arranque, desde un modo de edición simple pero efectivo.
El gestor de arranque Grub cada vez que creamos un nuevo kernel o lo cambiamos por que lo hemos recompilado, no hay que ejecutar nada más que el GRUB para que todo el sistema note el cambio.
El GRUB viene instalado por defecto en la mayoría de los sistemas operativos Linux y se lo puede usar para cualquier tipo de trabajo.
Otros gestores de arranque
GRUB supera la ventaja de los anteriores gestores de arranque. Tenemos el anterior gestor de arranque LILO, que fue popular antes de la llegado del gestor de arranque GRUB, pero varias empresas lo siguen utilizando. LILO funciona bien, pero carece de muchas funcionalidades del GRUB, por ejemplo:
No tiene ambiente gráfico amigable.
No permite editar en vivo los parámetros de arranque.
Cada vez que se cambia un kernel hay que ejecutar LILO para que tome un nuevo kernel, pues no acepta cambios en sus parámetros de arranque.
Cualquier falla en el gestor de arranque LILO conducía a que el sistema quede inoperante y a tener que arrancar en modo de rescate.
Otro gestor de arranque parecido a LILO que existia antes del GRUB tenemos el gestor SYSLINUX que es muy parecido a LILO en la forma que muestra en la pantalla (:); lo que diferencia de LILO es que el SYSLINUX permite pasarle algunos parámetros al sistema y, se configura en un solo archivo (sysLinux.cfg), lo que quiere decir es que no hay que volver a ejecutar el SYSLINUX para instalar nuevamente el gestor de arranque cuando cambia el kernel.
Gestor de arranque del GRUB
Proceso de arranque en un sistema x86 y GRUB
La etapa 1, o cargador de arranque primario, se lee en la memoria del BIOS o Master Boot Record (MBR), que existe este gestor en menos de 512 bytes de espacio en disco dentro del MBR y es capaz de arrancar, bien sea la etapa 1.5 o la etapa 2 del gestor de arranque del Grub.
La Etapa 1.5 del gestor de arranque se lee en la memoria por el gestor de arranque de la Etapa 1, si fuese necesario. Lo que sucede en la partición /boot que está por encima del cilindro 1024 del disco duro o cuando se usa LBA.
La Etapa 2 o el gestor de arranque secundario se lee en memoria, lo que visualiza el menú del GRUB y el entorno de los comandos, lo que le permite seleccionar que sistema operativo o kernel arrancar, pasar argumentos al kernel o ver los parámetros del sistema.
Al dar enter sobre uno de los kernels mostrados en el gestor de arranque secundario, este lee el sistema operativo o el kernel en la memoria.
Métodos de arranque del Grub
El método usado para arrancar los sistemas operativos Linux se conoce como el método de carga directa porque el gestor de arranque carga el sistema operativo directamente, pero los procesos de arranque de los sistemas operativos pueden varia, por ejemplo en los sistemas operativos comerciales, los de Microsoft, se carga mediante un método de arranque de carga encadenada.
GRUb soporta ambos métodos de arranque, directo y carga encadenada, permitiendo arrancar desde casi cualquier sistema operativo.
Conoce un poco más acerca de los métodos de Arranque del GRUB en los siguientes enlaces: Gestor de arranque GRUB
La automatización de tareas es un conjunto de facilidades para activar en un determinado momento un comando, programa o macro (script) que realice una o más tareas de administración, como decir por ejemplo, sacar respaldo, descargar archivos, borrar archivos, correr antivirus, comprimir archivos, chequear la integridad del sistema.
Existen tres alternativas o facilidades para automatizar tareas: cron, anacron y at.
Facilidad cron
La facilidad cron sirve para ejecutar periódicamente (cada hora, día, semana, mes) uno o varias tareas. La palabra cron viene del griego chronos que significa tiempo, este se imprementa mediante un demonio crond que lee el archivo de configuración /etc/crontab y ejecuta las tareas especificadas en el archivo crontab, este ejecuta cada minuto, hora, día, semana o mes o con la regularidad que se pide en el archivo crontab o script indicados en el mismo archivo.
Para activar el servicio crond se utiliza la siguiente instrucción de comando de Linux
service crond start
Para asegurarse de que el cond esta siendo ejecutado en su máquina cada vez que se incia, haga lo siguiente:
chkconfig crond on
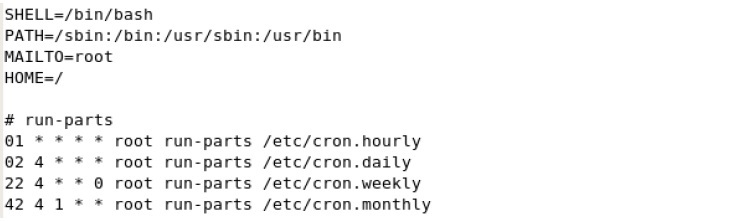
Para automatizar las tareas se utiliza el archivo /etc/crontab y los directorios asociados que facilitan la automatización , que son:
El contenido del archivo crontab tiene este contenido mínimo:
La primera linea lo que indica que el shell que ejecuta las tareas que este caso será el bash.
La segunda linea indica los directorios de búsqueda para localizar comandos que pueden haberse indicado dentro de las tareas.
La tercera línea MAILTO sirve para enviar al usuario indicado (root) un mensaje indicandole cada tarea realizada.
Luego viene la configuración de las tareas.
Consulta mas en automatización de tareas de Linux en el siguiente link